|
I am a third-year Ph.D. student at the Intelligent Vision Group (IVG), Department of Automation, Tsinghua University, advised by Prof. Jiwen Lu . Prior to that, I received my Bachelor's degree from the Department of Automation, Tsinghua University in 2023 (Ranking 1/170). I am broadly interested in large language model and computer vision. My current research focuses on multi-modal large language models and large vision models. |

|
|
* indicates equal contribution |

|
Zuyan Liu*, Yuhao Dong*, Ziwei Liu, Winston Hu, Jiwen Lu, Yongming Rao, International Conference on Learning Representations (ICLR), 2025 [arXiv] [Code] [Project Page] [中文解读] Oryx offers an on-demand solution to seamlessly and efficiently process visual inputs with arbitrary spatial sizes and temporal lengths. |

|
Zuyan Liu*, Yuhao Dong*, Jiahui Wang, Ziwei Liu, Winston Hu, Jiwen Lu, Yongming Rao arXiv, 2025 [arXiv] [Code] [Project Page] [中文解读] [Rank 1st on OpenCompass Leaderboard (<15B)] Ola is an Omni-modal Language model that achieves competitive performance across image, video, and audio understanding compared to specialized models, pushing the frontiers of the omni-modal language model. |
|
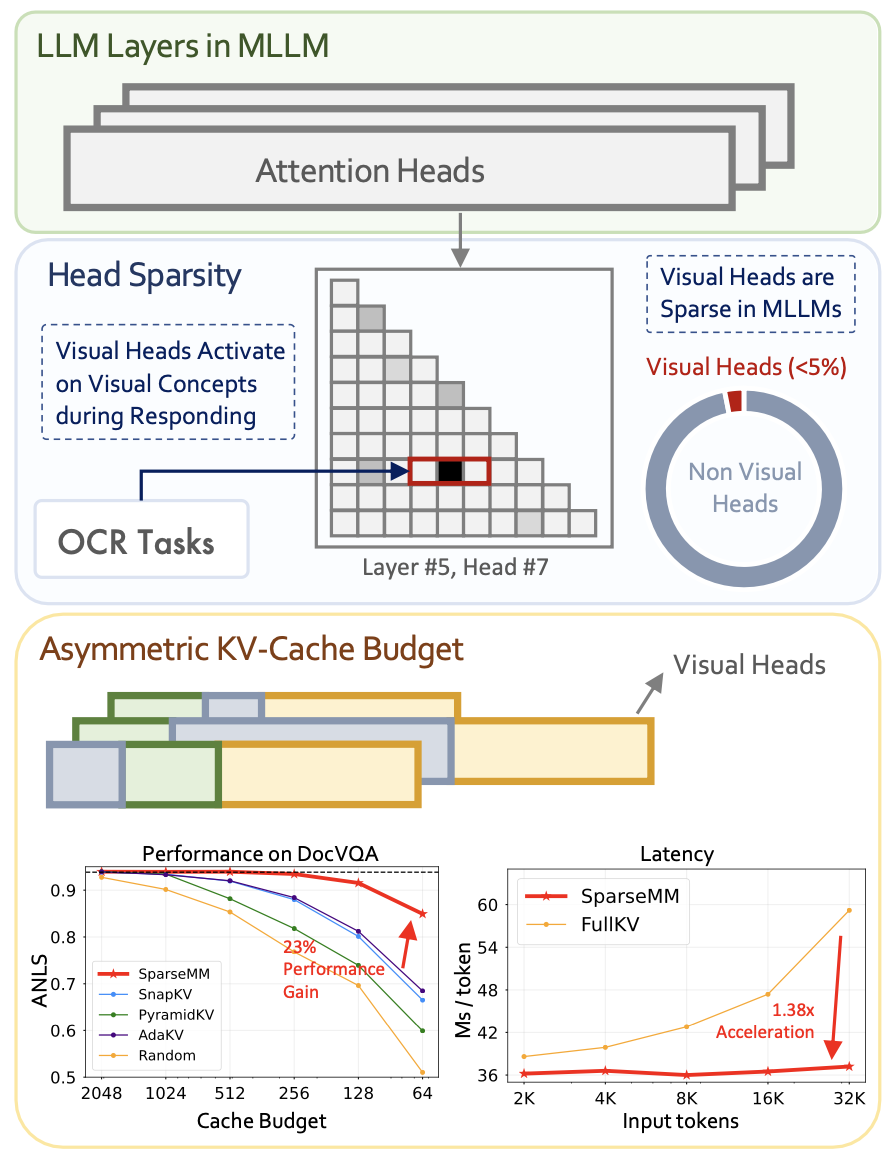
Jiahui Wang*, Zuyan Liu*, Yongming Rao, Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2025 [arXiv] [Code] [Project Page] [中文解读] SparseMM observe the sparsity of attention heads for vision-language multi-modal models, termed Visual Heads, and applies asymmetric operations to achieve model pruning and reasoning acceleration. |

|
Yuhao Dong*, Zuyan Liu*, Hailong Sun, Jingkang Yang, Winston Hu, Yongming Rao, Ziwei Liu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 Highlight [arXiv] [Code] [中文解读] Insight-V is a multi-agent system consisting of a reasoning agent dedicated to performing long-chain reasoning and a summary agent trained to judge and summarize reasoning results. |
|
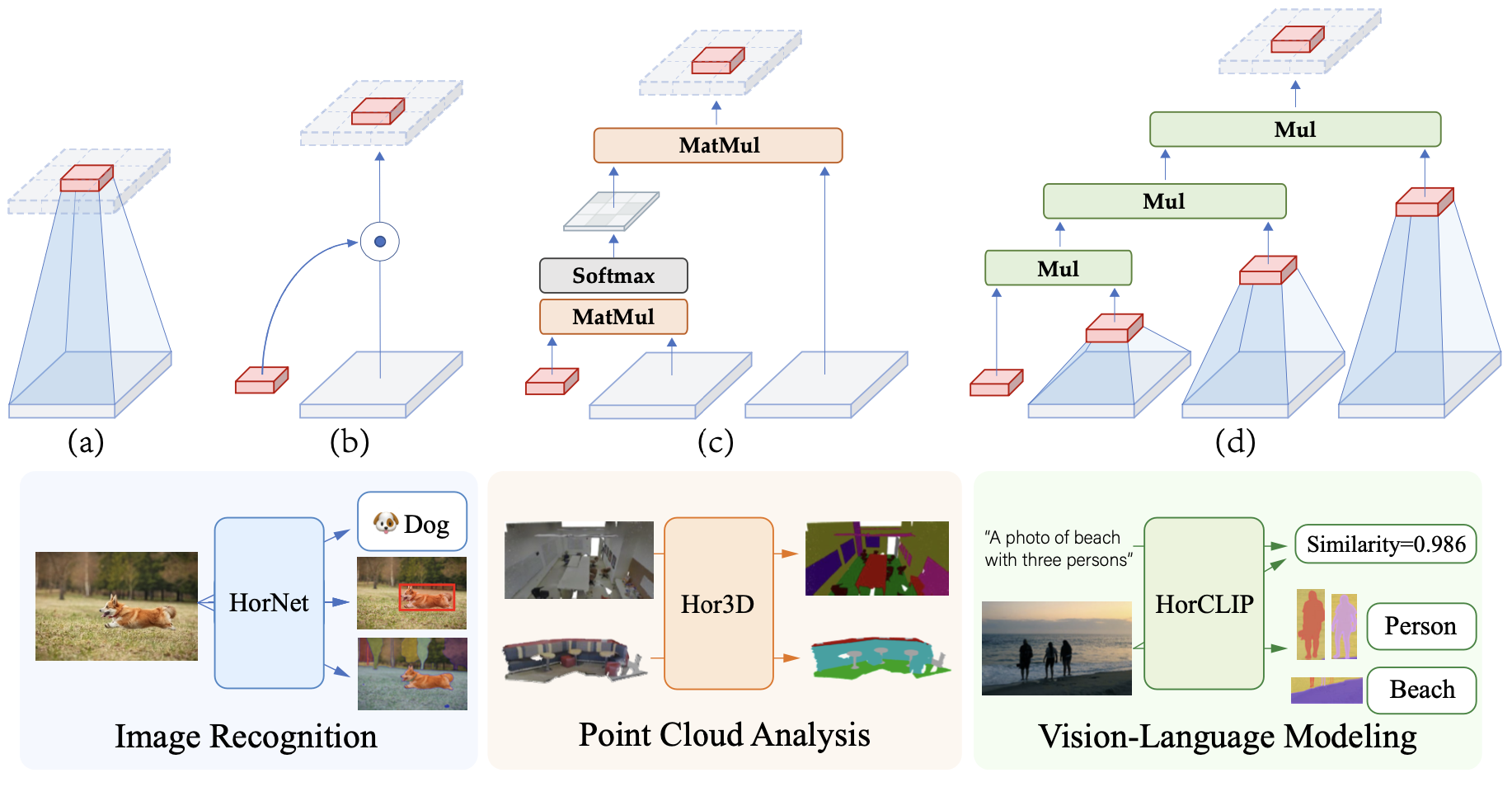
Zuyan Liu, Yongming Rao, Wenliang Zhao, Jie Zhou, Jiwen Lu IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF:18.6), 2025 [Paper] [Code] [Project Page] We propose the general HorNet-Family, including HorNet, Hor3D, and HorCLIP for a comprehensive visual fundamental architecture with better performance-efficiency trade-off. |
|
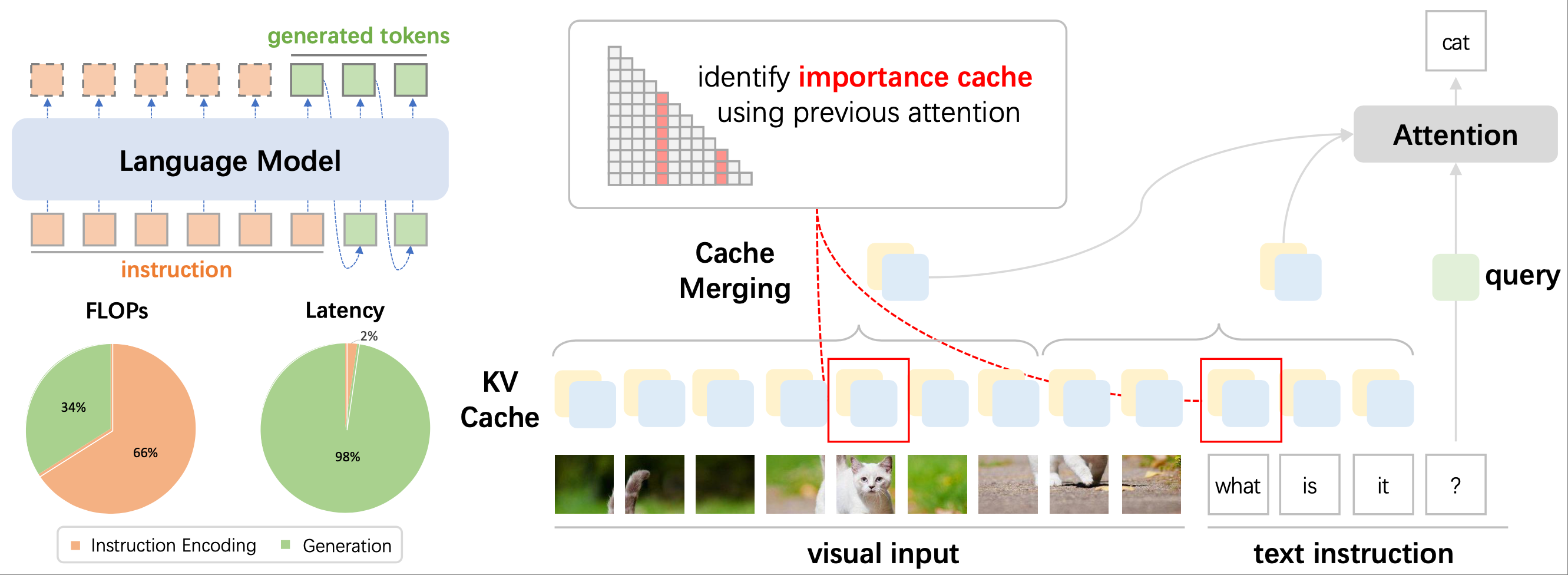
Zuyan Liu, Benlin Liu, Jiahui Wang, Yuhao Dong, Guangyi Chen, Ranjay Krishna, Yongming Rao, Jiwen Lu European Conference on Computer Vision (ECCV), 2024 [arXiv] [Code] [Project Page] Elastic Cache is a novel approach for KV Cache acceleration in multi-modal large language models that benefits from applying distinct acceleration methods for instruction encoding and output generation stages. |

|
Zuyan Liu*, Yuhao Dong*, Yongming Rao, Jie Zhou, Jiwen Lu arXiv, 2024 [arXiv] [Code] [Project Page] The Chain-of-Spot (CoS) method is an approach that enhances feature extraction by focusing on key regions of interest (ROI) within the image, corresponding to the posed questions or instructions. |
|
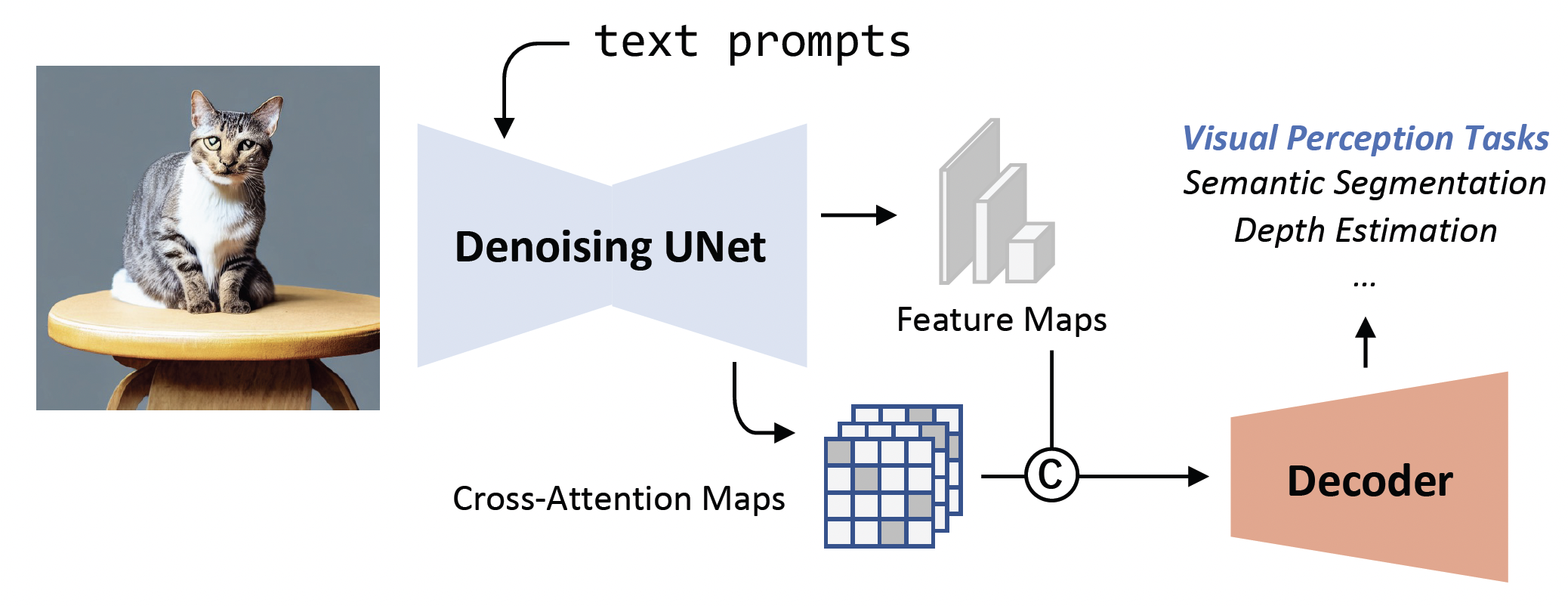
Wenliang Zhao*, Yongming Rao*, Zuyan Liu*, Benlin Liu Jie Zhou, Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2023 [arXiv] [Code] [Project Page] [Rank 1st on NYUv2 Depth Estimation] VPD (Visual Perception with Pre-trained Diffusion Models) is a framework that leverages the high-level and low-level knowledge of a pre-trained text-to-image diffusion model to downstream visual perception tasks. |

|
Yongming Rao*, Zuyan Liu*, Wenliang Zhao*, Jie Zhou, Jiwen Lu IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF:24.31), 2023 [arXiv] [Code] [Project Page] The dynamic spatial sparsification framework can be applied to general visual architectures (e.g. Transformers, ConvNeXt, Swin Transformers) and visual tasks (e.g. classification, object detection, semantic segmentation) for efficient inference. |

|
Wenliang Zhao, Yongming Rao*, Weikang Shi, Zuyan Liu, Wenliang Zhao*, Jie Zhou, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023 [arXiv] [Code] DiffSwap is a diffusion model based framework for high-fidelity and controllable face swapping. |

|
Xumin Yu*, Yongming Rao*, Ziyi Wang, Zuyan Liu, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 Oral Presentation [arXiv] [Code] [中文解读] PoinTr is a transformer-based framework that reformulates point cloud completion as a set-to-set translation problem. |
|
|

|
Multi-Modal Model Group, Research Intern Topic: Multi-Modal |

|
Seed Vision Group, Research Intern Topic: Video Generation |

|
Vision Model Research Center, Research Intern Topic: Multi-Modal |

|
Intelligent Creation Group, Research Intern Topic: Human AIGC |
|
|
|
|
|
|
© Zuyan Liu | Last updated: May 25, 2025